跟 GPT 学 AI:线性回归和逻辑回归代价函数解析
mylxsw, 9/3/2024 • machine-learning
这段内容我不太理解,请通俗易懂的向我解释一下:
这段内容主要是解释两种不同的代价函数(Cost Function),用于线性回归和逻辑回归的区别。
- 线性回归的代价函数:
首先,对于线性回归(Linear Regression),代价函数(也叫损失函数)用于衡量模型预测值与实际值之间的差距。代价函数的公式是:
其中, 是模型的预测值, 是实际值, 是样本的总数。这个代价函数的核心思想是最小化预测值和实际值的平方差。
- 逻辑回归的代价函数:
逻辑回归(Logistic Regression)用于分类问题,它的代价函数不能直接使用线性回归的平方差代价函数。因为逻辑回归的输出是一个概率值(0到1之间),我们希望这个代价函数能够反映模型在分类任务中的表现。于是,引入了下面的代价函数:
其中, 的定义为:
解释一下这个公式:
- 当实际值 时,我们希望预测值 越接近 1 越好,如果预测结果接近 0(错误分类),那么代价就会变得非常大(因为 会趋向无穷大)。
- 当实际值 时,我们希望预测值 越接近 0 越好,如果预测结果接近 1(错误分类),同样代价也会变得非常大(因为 会趋向无穷大)。
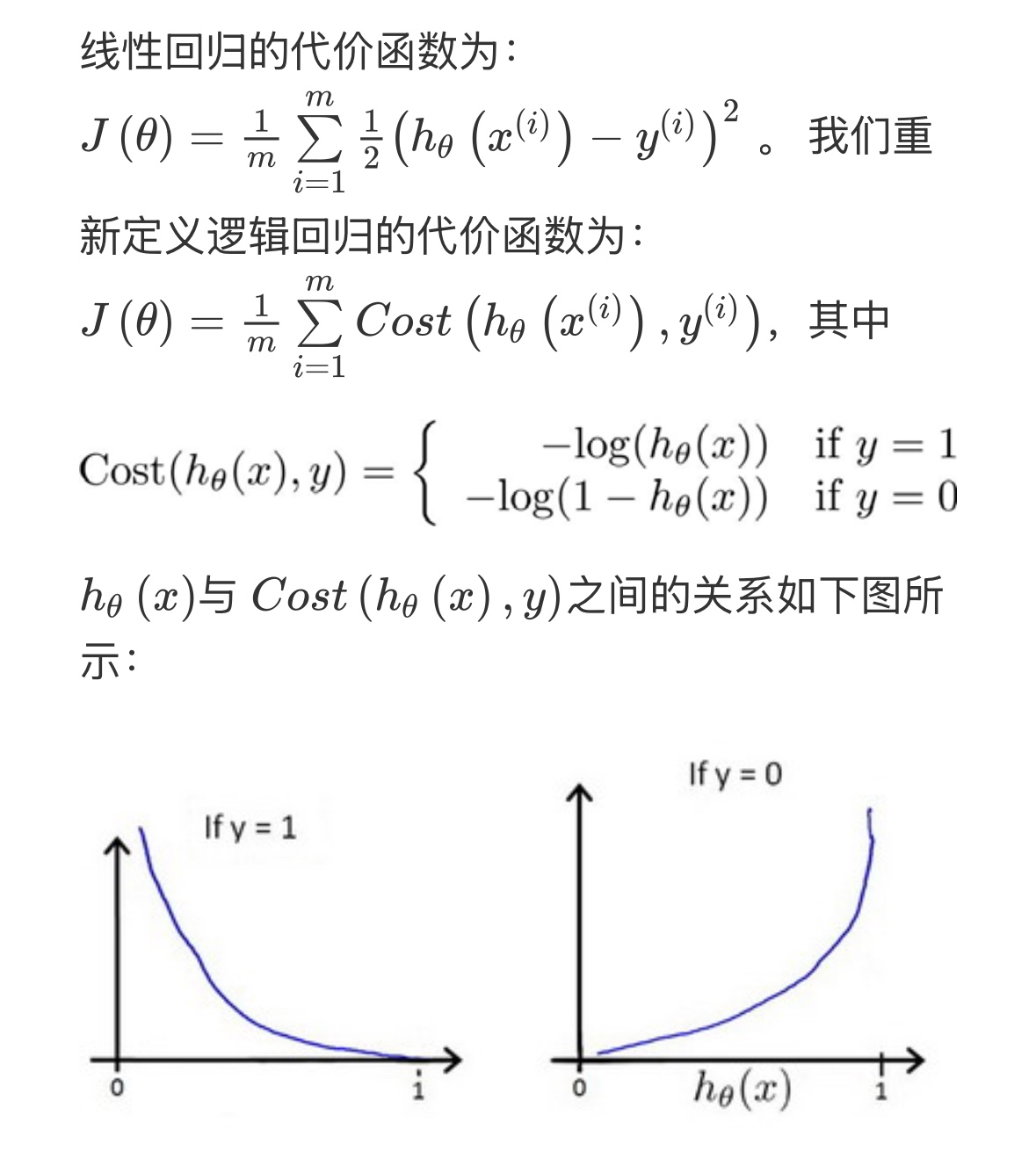
- 图的解释:
右边的两幅图说明了代价函数的行为:
- 如果 ,那么当 越接近 1,代价 越小。
- 如果 ,那么当 越接近 0,代价 越小。
总之,这个代价函数帮助逻辑回归模型在训练过程中不断调整参数,以便最小化错误分类的概率。