MongoDB 新手入门 - Aggregation
本文是 MongoDB 新手入门 系列的第二篇,在本文中,我们将会讲解 MongoDB 的聚合框架,在看完本文后,读者可以掌握使用 MongoDB 进行常用的数据统计分析方法。
本文将会持续修正和更新,最新内容请参考我的 GITHUB (opens in a new tab) 上的 程序猿成长计划 (opens in a new tab) 项目,欢迎 Star,更多精彩内容请 follow me (opens in a new tab)。
简介
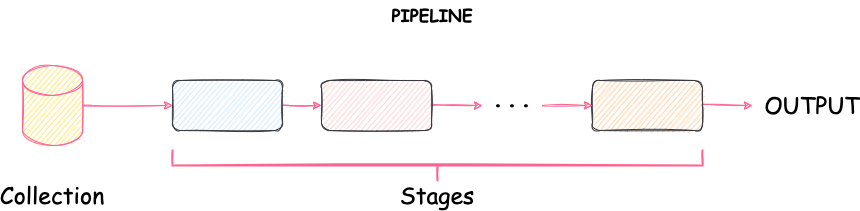
聚合管道(Aggregation Pipelines)中包含一个或多个用于处理文档的步骤(stages):
- 每一个步骤(stage)都会对输入的文档执行某个操作,例如,
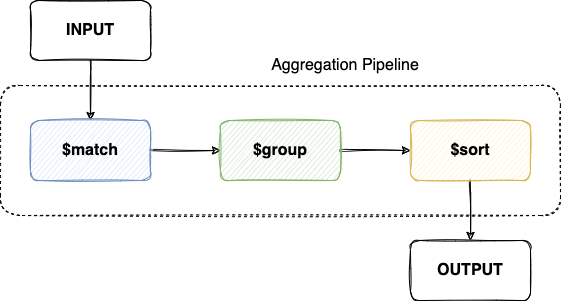
$match步骤可以用于筛选文档,$group步骤可以对文档进行分组并且计算字段的平均值 - 每个步骤的输出文档将会作为下一个步骤的输入文档
- 所有步骤执行完成后,聚合管道会返回文档处理后的结果,比如返回当前值,平均值,最大值和最小值等
MongoDB 4.2 开始,可以使用聚合管道来更新文档了。
聚合管道的语法为
db.collection.aggregate( [ { <stage> }, ... ] )为了演示聚合管道的功能,我们现在 MongoDB 中创建一个 orders 集合,插入以下数据
db.orders.insertMany( [
{ _id: 0, name: "Pepperoni", size: "small", price: 19,
quantity: 10, date: ISODate( "2021-03-13T08:14:30Z" ) },
{ _id: 1, name: "Pepperoni", size: "medium", price: 20,
quantity: 20, date : ISODate( "2021-03-13T09:13:24Z" ) },
{ _id: 2, name: "Pepperoni", size: "large", price: 21,
quantity: 30, date : ISODate( "2021-03-17T09:22:12Z" ) },
{ _id: 3, name: "Cheese", size: "small", price: 12,
quantity: 15, date : ISODate( "2021-03-13T11:21:39.736Z" ) },
{ _id: 4, name: "Cheese", size: "medium", price: 13,
quantity:50, date : ISODate( "2022-01-12T21:23:13.331Z" ) },
{ _id: 5, name: "Cheese", size: "large", price: 14,
quantity: 10, date : ISODate( "2022-01-12T05:08:13Z" ) },
{ _id: 6, name: "Vegan", size: "small", price: 17,
quantity: 10, date : ISODate( "2021-01-13T05:08:13Z" ) },
{ _id: 7, name: "Vegan", size: "medium", price: 18,
quantity: 10, date : ISODate( "2021-01-13T05:10:13Z" ) }
] )下面的示例会计算两个日期之间每天的的披萨订单总价值和平均数量
// SQL:SELECT
// DATE_FORMAT(date, '%Y-%m-%d') AS _id,
// SUM(price * quantity) AS totalOrderValue,
// AVG(quantity) AS averageOrderQuantity
// FROM orders
// WHERE date >= '2020-01-30' AND date < '2022-01-30'
// GROUP BY DATE_FORMAT(date, '%Y-%m-%d')
// ORDER BY SUM(price * quantity) DESC
db.orders.aggregate( [
// Stage 1: 通过时间范围过滤披萨订单
{
$match:
{
"date": { $gte: new ISODate( "2020-01-30" ), $lt: new ISODate( "2022-01-30" ) }
}
},
// Stage 2: 对匹配的订单进行分组,并且计算总价值和平均数量
{
$group:
{
_id: { $dateToString: { format: "%Y-%m-%d", date: "$date" } },
totalOrderValue: { $sum: { $multiply: [ "$price", "$quantity" ] } },
averageOrderQuantity: { $avg: "$quantity" }
}
},
// Stage 3: 按照 totalOrderValue 对文档进行反向排序
{
$sort: { totalOrderValue: -1 }
}
] )命令输出如下所示
[
{ _id: '2022-01-12', totalOrderValue: 790, averageOrderQuantity: 30 },
{ _id: '2021-03-13', totalOrderValue: 770, averageOrderQuantity: 15 },
{ _id: '2021-03-17', totalOrderValue: 630, averageOrderQuantity: 30 },
{ _id: '2021-01-13', totalOrderValue: 350, averageOrderQuantity: 10 }
]系统变量
在聚合管道的步骤中可以使用系统变量或者用户自定义的变量,变量可以是任意的 BSON 类型数据,要访问变量的值,使用前缀 $$, 如 $$<variable>。如果变量引用的是一个对象,可以这样访问指定的字段 $$<variable>.<field>。
MongoDB 中定义了以下系统变量
| 变量 | 描述 |
|---|---|
| NOW | 当前日期时间 |
| CLUSTER_TIME | 当前时间戳,CLUSTER_TIME 只在副本集和分片集群中有效 |
| ROOT | 引用根文档 |
| CURRENT | 引用聚合管道正在处理的字段路径开始部分,除非特别说明,所有的 stage 开始的时候 $CURRENT 都和 $ROOT 相同。$CURRENT 是可修改的,$<field> 等价于 $$CURRENT.<field>,重新绑定 CURRENT 会改变 $ 的含义 |
| REMOVE | 标识值为缺失,用于按条件来排除字段,配合 $project使用时,把一个字段设置为变量 REMOVE 可以在输出中排除这个字段,参考 有条件的排除字段 (opens in a new tab) |
| DESCEND | $redact (opens in a new tab) 表达式允许的结果之一 |
| PRUNE | $redact (opens in a new tab) 表达式允许的结果之一 |
| KEEP | $redact (opens in a new tab) 表达式允许的结果之一 |
这里以 $$REMOVE 为例,说明系统变量的使用
db.books.aggregate( [
{
$project: {
title: 1,
"author.first": 1,
"author.last" : 1,
"author.middle": {
// 这里判断 $author.middle 是否为空,为空则将该字段移除,否则返回该字段
$cond: {
if: { $eq: [ "", "$author.middle" ] },
then: "$$REMOVE",
else: "$author.middle"
}
}
}
}
] )这里的
$cond(opens in a new tab) 操作符用于计算一个 Bool 表达式,类似于编程语言中的三元运算符。
聚合管道中常用的步骤
在 db.collection.aggreagte() 方法中,除了 $out,$merge,$geoNear 之外,其它的 stage 都可以出现多次。
| Stage | 描述 |
|---|---|
$addFields (opens in a new tab) | 在文档中添加新的字段,与 $project 类似,$addFields 会在文档中添加新的字段,$set 是 $addFields 的别名 |
$bucket (opens in a new tab) | 根据指定的表达式和桶边界将传入的文档分组,这些组称之为存储桶 |
$bucketAuto (opens in a new tab) | 同 $bucket,只不过该 stage 会自动的确定存储桶的边界,尝试将文档均匀的分配到指定数量的存储桶中 |
$collStats (opens in a new tab) | 返回关于集合或者视图的统计信息 |
$count (opens in a new tab) | 返回聚合管道在当前 stage 中的文档总数 |
$facet (opens in a new tab) | 对同一批输入文档,在一个 stage 中处理多个聚合管道,每一个子管道都有它自己的输出文档,最终的结果是一个文档数组 |
$geoNear (opens in a new tab) | 根据地理空间位置的远近返回排序后的文档流,结合 $match,$sort 和 $limit 的功能。输出文档中添加了一个额外的距离字段 |
$graphLookup (opens in a new tab) | 在集合上执行递归搜索,对于每一个输出的文档都添加一个新的数组字段,该字段包含了对文档进行递归搜索的遍历结果 |
$group (opens in a new tab) | 通过指定的表达式对文档进行分组,并且对每个分组应用累加表达式 |
$indexStats (opens in a new tab) | 返回集合中每个索引的统计信息 |
$limit (opens in a new tab) | 限制返回的文档数量 |
$listSessions (opens in a new tab) | 列出在 system.sessions 集合中所有的会话记录 |
$lookup (opens in a new tab) | 对同一个数据库中的集合执行执行左外连接(left outer join)操作 |
$match (opens in a new tab) | 文档过滤 |
$merge (opens in a new tab) | MongoDB 4.2 新增功能,将聚合管道的输出文档写入到一个集合。当前 stage 可以将合并结果纳入到输出集合中。该 stage 必须是管道中的最后一个 stage |
$out (opens in a new tab) | 将聚合管道的结果写入到一个集合中,该 stage 必须是管道中的最后一个 stage |
$planCacheStats (opens in a new tab) | 返回集合的计划缓存 (opens in a new tab)信息 |
$project (opens in a new tab) | 对集合文档返回的字段进行处理,新增或者删除字段 |
$redact (opens in a new tab) | 通过文档本身存储的信息限制每个文档的内容,等价于 $project 和 $match 一起使用,可以用来实现字段级的修订,对于每个输入的文档,输出1个或者0个文档 |
$replaceRoot (opens in a new tab) | 使用指定的内嵌文档替换当前文档。该操作会替换输入文档中包含 _id 在内的所有已经存在的字段 |
$replaceWith (opens in a new tab) | $replaceRoot 操作的别名 |
$sample (opens in a new tab) | 从输入文档中随机选择指定数量的文档 |
$search (opens in a new tab) | 对文档执行全文搜索(只在 MongoDB Atlas 集群中有效,本地部署服务不可用) |
$set (opens in a new tab) | 为文档添加新的字段,与 $project 类似, $set 会在输出文档中添加新的字段。$set 是 $addFields 的别名 |
$setWindowFields (opens in a new tab) | MongoDB 4.0 新增功能,将文档以窗口的形式分组,然后对于每一个窗口的文档执行一个或者多个操作 |
$skip (opens in a new tab) | 跳过指定数量的文档 |
$sort (opens in a new tab) | 按照指定的 Key 对文档进行排序 |
$sortByCount (opens in a new tab) | 对输入的文档基于指定的表达式进行分组,然后计算每一个唯一组中文档的数量 |
$unionWith (opens in a new tab) | MongoDB 4.4 新增功能,对两个集合执行合并操作,例如将两个集合中的结果合并为一个结果集 |
$unset (opens in a new tab) | 从文档中移除指定字段 |
$unwind (opens in a new tab) | 将文档中的数组字段拆分为多个文档 |
本文只对常用的几个 stage 进行重点介绍,它们分别是 $match,$count,$limit,$project,$lookup,$group,$facet,$unwind,$bucket,$bucketAuto。
文档过滤 $match
$match 用于过滤筛选文档,语法如下
{ $match: { <query> } }在 MongoDB 中创建名为 articles 的集合
{ "_id" : ObjectId("512bc95fe835e68f199c8686"), "author" : "dave", "score" : 80, "views" : 100 }
{ "_id" : ObjectId("512bc962e835e68f199c8687"), "author" : "dave", "score" : 85, "views" : 521 }
{ "_id" : ObjectId("55f5a192d4bede9ac365b257"), "author" : "ahn", "score" : 60, "views" : 1000 }
{ "_id" : ObjectId("55f5a192d4bede9ac365b258"), "author" : "li", "score" : 55, "views" : 5000 }
{ "_id" : ObjectId("55f5a1d3d4bede9ac365b259"), "author" : "annT", "score" : 60, "views" : 50 }
{ "_id" : ObjectId("55f5a1d3d4bede9ac365b25a"), "author" : "li", "score" : 94, "views" : 999 }
{ "_id" : ObjectId("55f5a1d3d4bede9ac365b25b"), "author" : "ty", "score" : 95, "views" : 1000 }执行查询
// SQL:SELECT * FROM articles WHERE author = "dave"
db.articles.aggregate(
[ { $match : { author : "dave" } } ]
);查询结果
{ "_id" : ObjectId("512bc95fe835e68f199c8686"), "author" : "dave", "score" : 80, "views" : 100 }
{ "_id" : ObjectId("512bc962e835e68f199c8687"), "author" : "dave", "score" : 85, "views" : 521 }文档计数 $count
$count 用于统计输入中的文档数量,语法如下
{ $count: <string> }这里的 <string> 是输出字段的名称。
db.getCollection("orders").aggregate([
{ $match: {price: {$gt: 15}} },
{ $count: "price_gt_15_count" }
])输出
{"price_gt_15_count" : NumberInt(5) }文档数量限制 $limit
$limit 用于控制传递给下一个 stage 的文档数量,语法为
{ $limit: <positive 64-bit integer> }比如只返回 2 条数据
db.getCollection("orders").aggregate([{$limit: 2}])文档字段映射 $project
$project 用于控制文档中包含的字段,类似于 SQL 中的 AS,它会把文档中指定的字段传递个下一个 stage。
语法为
{ $project: { <specification(s)> } }这里的 <specification(s)> 支持以下形式
| 形式 | 说明 |
|---|---|
<field>: <1 or true> | 指定包含字段,非 0 的整数都为 true |
_id: <0 or false> | 指定消除 _id 字段,默认是包含 _id 字段的 |
<field>: <expression> | 添加新字段或者是覆盖已有字段 |
<field>: <0 or false> | 指定排除字段 |
查询订单,只返回名称和尺寸
// SQL:SELECT name, size FROM orders WHERE quantity > 20
db.orders.aggregate([
{ $match: { quantity: { $gt: 20 } } },
{ $project: { name: true, size: 1, _id: false } }
])返回值如下
{ "name" : "Pepperoni", "size" : "large" }
{ "name" : "Cheese", "size" : "medium" }左外连接 $lookup
$lookup 用于对同一个数据库中的集合进行 left outer join 操作。
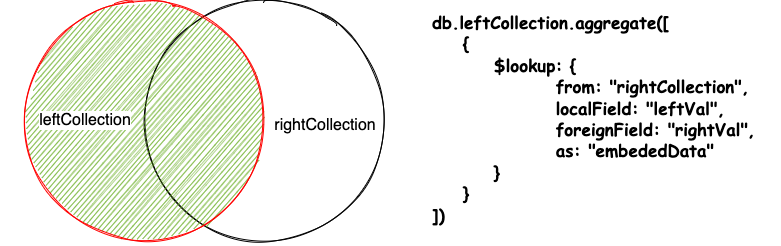
单个 Join 条件的等值匹配
语法如下
{
$lookup:
{
from: <collection to join>,
localField: <field from the input documents>,
foreignField: <field from the documents of the "from" collection>,
as: <output array field>
}
}参数
from: 指定要进行关联的集合,from集合不能是分片集合localField:输入文档中用于关联的字段,localField的值与from集合中的foreignField相等,如果输入文档中不包含localField,则该值为nullforeignField: 指定from集合中的关联字段,如果集合中没有该字段,则认为其为nullas: 指定要添加到输入文档中的数组字段名称。这个数组字段包含了from集合中匹配的文档。如果指定的字段名在输入文档中已经存在,则覆盖该字段
这个操作等价于以下的伪 SQL:
SELECT *, <output array field>
FROM collection
WHERE <output array field> IN (
SELECT *
FROM <collection to join>
WHERE <foreignField> = <collection.localField>
);我们先在 orders 集合中插入几个文档
db.orders.insertMany( [
{ "_id" : 1, "item" : "almonds", "price" : 12, "quantity" : 2 },
{ "_id" : 2, "item" : "pecans", "price" : 20, "quantity" : 1 },
{ "_id" : 3 }
] )然后创建另外一个 inventory 集合
db.inventory.insertMany( [
{ "_id" : 1, "sku" : "almonds", "description": "product 1", "instock" : 120 },
{ "_id" : 2, "sku" : "bread", "description": "product 2", "instock" : 80 },
{ "_id" : 3, "sku" : "cashews", "description": "product 3", "instock" : 60 },
{ "_id" : 4, "sku" : "pecans", "description": "product 4", "instock" : 70 },
{ "_id" : 5, "sku": null, "description": "Incomplete" },
{ "_id" : 6 }
] )下面的查询使用 orders 集合来关联 inventory 集合,使用 item 和 sku 来进行关联
// SQL:SELECT *, inventory_docs
// FROM orders
// WHERE inventory_docs IN (
// SELECT *
// FROM inventory
// WHERE sku = orders.item
// );
db.orders.aggregate( [
{
$lookup:
{
from: "inventory",
localField: "item",
foreignField: "sku",
as: "inventory_docs"
}
}
] )该操作返回值如下
{
"_id" : 1,
"item" : "almonds",
"price" : 12,
"quantity" : 2,
"inventory_docs" : [
{ "_id" : 1, "sku" : "almonds", "description" : "product 1", "instock" : 120 }
]
}
{
"_id" : 2,
"item" : "pecans",
"price" : 20,
"quantity" : 1,
"inventory_docs" : [
{ "_id" : 4, "sku" : "pecans", "description" : "product 4", "instock" : 70 }
]
}
{
"_id" : 3,
"inventory_docs" : [
{ "_id" : 5, "sku" : null, "description" : "Incomplete" },
{ "_id" : 6 }
]
}联表后的集合上的 Join 条件和子查询
语法如下
{
$lookup:
{
from: <joined collection>,
let: { <var_1>: <expression>, …, <var_n>: <expression> },
pipeline: [ <pipeline to run on joined collection> ],
as: <output array field>
}
}参数:
let:可选参数,指定了在 pipeline 步骤中可以使用的变量,这些变量用于作为 pipeline 的输入访问联表后的集合文档。在 pipeline 中使用$$<variable>语法来访问变量pipeline:指定在联表后的集合上执行的 pipeline,这些 pipeline 决定了联表后集合的输出,要返回所有文档的话,指定 pipeline 为[]
该操作等价于下面的伪 SQL:
SELECT *, <output array field>
FROM collection
WHERE <output array field> IN (
SELECT <documents as determined from the pipeline>
FROM <collection to join>
WHERE <pipeline>
);我们首先创建下面两个集合
db.orders.insertMany( [
{ "_id" : 1, "item" : "almonds", "price" : 12, "ordered" : 2 },
{ "_id" : 2, "item" : "pecans", "price" : 20, "ordered" : 1 },
{ "_id" : 3, "item" : "cookies", "price" : 10, "ordered" : 60 }
] )
db.warehouses.insertMany( [
{ "_id" : 1, "stock_item" : "almonds", warehouse: "A", "instock" : 120 },
{ "_id" : 2, "stock_item" : "pecans", warehouse: "A", "instock" : 80 },
{ "_id" : 3, "stock_item" : "almonds", warehouse: "B", "instock" : 60 },
{ "_id" : 4, "stock_item" : "cookies", warehouse: "B", "instock" : 40 },
{ "_id" : 5, "stock_item" : "cookies", warehouse: "A", "instock" : 80 }
] )执行查询
// SQL: SELECT *, stockdata
// FROM orders
// WHERE stockdata IN (
// SELECT warehouse, instock
// FROM warehouses
// WHERE stock_item = orders.item
// AND instock >= orders.ordered
// );
db.orders.aggregate( [
{
$lookup:
{
from: "warehouses",
let: { order_item: "$item", order_qty: "$ordered" },
pipeline: [
{ $match:
{ $expr:
{ $and:
[
{ $eq: [ "$stock_item", "$$order_item" ] },
{ $gte: [ "$instock", "$$order_qty" ] }
]
}
}
},
{ $project: { stock_item: 0, _id: 0 } }
],
as: "stockdata"
}
}
] )该操作返回以下结果
{
_id: 1,
item: 'almonds',
price: 12,
ordered: 2,
stockdata: [
{ warehouse: 'A', instock: 120 },
{ warehouse: 'B', instock: 60 }
]
},
{
_id: 2,
item: 'pecans',
price: 20,
ordered: 1,
stockdata: [ { warehouse: 'A', instock: 80 } ]
},
{
_id: 3,
item: 'cookies',
price: 10,
ordered: 60,
stockdata: [ { warehouse: 'A', instock: 80 } ]
}使用简洁语法的相关子查询
该特性为 MongoDB 5.0 的新功能。从 MongoDB 5.0 开始,可以使用简洁的语法进行相关子查询,相关子查询的子查询文档字段来自于连接的 foreign 和 local 集合。
下面是新的简洁的语法,它移除了 $expr 表达式中 foreign 和 local 字段的等值匹配:
{
$lookup:
{
from: <foreign collection>,
localField: <field from local collection's documents>,
foreignField: <field from foreign collection's documents>,
let: { <var_1>: <expression>, …, <var_n>: <expression> },
pipeline: [ <pipeline to run> ],
as: <output array field>
}
}该操作的伪 SQL 如下
SELECT *, <output array field>
FROM localCollection
WHERE <output array field> IN (
SELECT <documents as determined from the pipeline>
FROM <foreignCollection>
WHERE <foreignCollection.foreignField> = <localCollection.localField>
AND <pipeline match condition>
);分组 $group
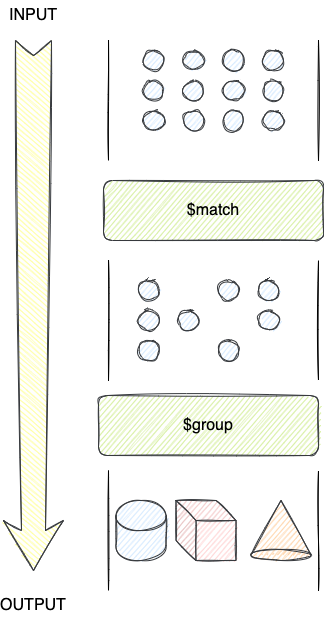
$group 对输入的文档按照指定的 _id 表达式进行分组,语法如下
{
$group:
{
_id: <expression>, // Group By Expression
<field1>: { <accumulator1> : <expression1> },
...
}
}选项 _id 指定了用于分组的 key 表达式,类似于 SQL 中的 group by,如果设置为 null 或者任何常数值,则对所有的文档作为一个整体进行计算。
accumulator 支持以下操作
| 名称 | 描述 |
|---|---|
$accumulator (opens in a new tab) | 用户定义的 accumulator 函数执行结果 |
$addToSet (opens in a new tab) | 为每一个分组返回唯一性表达式值的数组,数组元素的顺序不确定 |
$avg (opens in a new tab) | 数值型值的平均值,非数值型的值会被忽略 |
$count (opens in a new tab) | 分组包含的文档数量 |
$first (opens in a new tab) | 分组中的第一个文档 |
$last (opens in a new tab) | 分组中的最后一个文档 |
$max (opens in a new tab) | 分组中的最大值 |
$mergeObjects (opens in a new tab) | 将分组中的文档合并到一起做为一个文档 |
$min (opens in a new tab) | 分组中的最小值 |
$push (opens in a new tab) | 返回每个分组中文档的表达式值数组 |
$stdDevPop (opens in a new tab) | 输入值的总体标准偏差 |
$stdDevSamp (opens in a new tab) | 输入值的样本标准偏差 |
$sum (opens in a new tab) | 数值型值的总和,非数值型将会被忽略 |
默认情况下,
$group步骤有 100M 的内存限制,如果超过这个限制将会报错。可以使用 allowDiskUse (opens in a new tab) 选项来启用磁盘临时文件来解决这个问题。
统计不同大小的披萨订单销售总量
db.getCollection("orders").aggregate(
[
{
$group : {
_id : "$size",
count : { $sum : 1 }
}
}
],
{
"allowDiskUse" : true
}
);输出如下
{ "_id" : "medium", "count" : 3.0 }
{ "_id" : "small", "count" : 3.0 }
{ "_id" : "large", "count" : 2.0 }查询订单中有几种尺寸的披萨
db.getCollection("orders").aggregate([
{
$group: {_id: "$size"}
}
]);输出如下
{ "_id" : "medium" }
{ "_id" : "large" }
{ "_id" : "small" }查询销量大于等于 3 个的披萨尺寸
类似于 SQL 中的 GROUP BY ... HAVING COUNT(*) >= 3
// SQL: SELECT size as _id, count(*) as count FROM orders GROUP BY size HAVING COUNT(*) >= 3
db.getCollection("orders").aggregate(
[
{
$group : {
_id : "$size",
count : { $sum : 1 }
}
},
{
$match: { count: { $gte: 3} }
}
]
);输出如下
{ "_id" : "medium", "count" : 3.0 }
{ "_id" : "small", "count" : 3.0 }对披萨订单按照尺寸分组,返回每个组中披萨的名称集合
db.getCollection("orders").aggregate([
{
$group: {
_id: "$size",
names: { $push: "$name" }
}
}
])输出如下
{ "_id" : "large", "names" : [ "Pepperoni", "Cheese" ] }
{ "_id" : "small", "names" : [ "Pepperoni", "Cheese", "Vegan" ] }
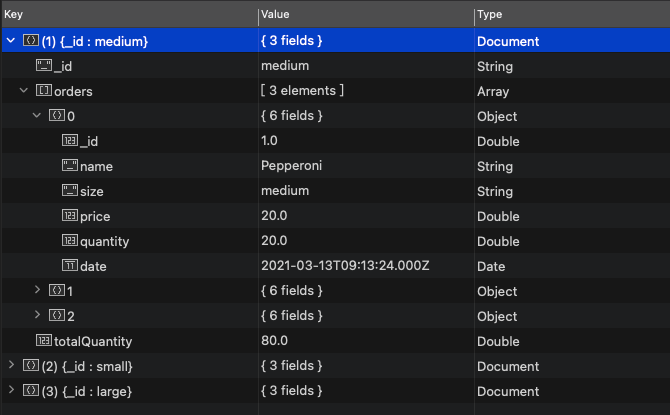
{ "_id" : "medium", "names" : [ "Pepperoni", "Cheese", "Vegan" ] }按照披萨订单尺寸分组,返回包含的订单以及披萨数量
db.getCollection("orders").aggregate([
{ $group: { _id: "$size", orders: { $push: "$$ROOT" } } },
{
$addFields: {
totalQuantity: { $sum: "$orders.quantity" }
}
}
])输出如下
这里的
$$ROOT是 MongoDB 中内置的系统变量,引用了根文档(顶级文档),这里通过该变量和$push操作,将文档放到了分组后新文档的orders字段,更多系统变量见下一章节。
多切面文档聚合 $facet
$facet 用于在一个 stage 中对同一批文档执行多个聚合管道处理。每一个聚合管道的输出文档都有自己的字段,最终输出是这些管道的结果数组。
输入文档只传递给
$facet阶段一次,它可以在同一批输入文档集合上执行不同的聚合操作。
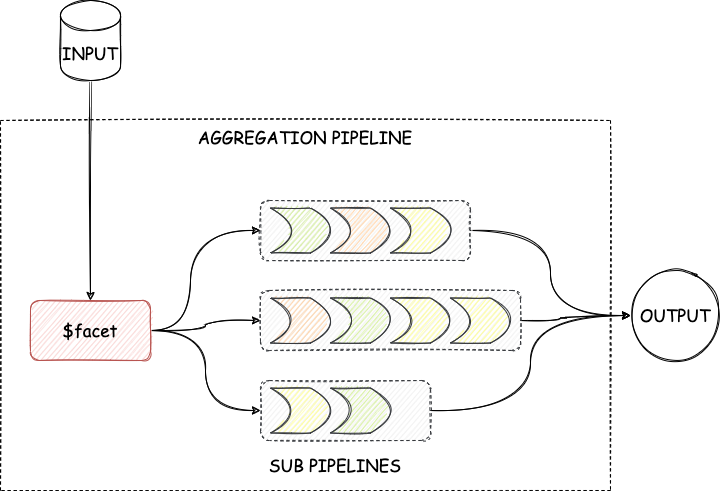
语法如下
{ $facet:
{
<outputField1>: [ <stage1>, <stage2>, ... ],
<outputField2>: [ <stage1>, <stage2>, ... ],
...
}
}创建一个名为 artwork 的集合
{ "_id" : 1, "title" : "The Pillars of Society", "artist" : "Grosz", "year" : 1926,
"price" : NumberDecimal("199.99"),
"tags" : [ "painting", "satire", "Expressionism", "caricature" ] }
{ "_id" : 2, "title" : "Melancholy III", "artist" : "Munch", "year" : 1902,
"price" : NumberDecimal("280.00"),
"tags" : [ "woodcut", "Expressionism" ] }
{ "_id" : 3, "title" : "Dancer", "artist" : "Miro", "year" : 1925,
"price" : NumberDecimal("76.04"),
"tags" : [ "oil", "Surrealism", "painting" ] }
{ "_id" : 4, "title" : "The Great Wave off Kanagawa", "artist" : "Hokusai",
"price" : NumberDecimal("167.30"),
"tags" : [ "woodblock", "ukiyo-e" ] }
{ "_id" : 5, "title" : "The Persistence of Memory", "artist" : "Dali", "year" : 1931,
"price" : NumberDecimal("483.00"),
"tags" : [ "Surrealism", "painting", "oil" ] }
{ "_id" : 6, "title" : "Composition VII", "artist" : "Kandinsky", "year" : 1913,
"price" : NumberDecimal("385.00"),
"tags" : [ "oil", "painting", "abstract" ] }
{ "_id" : 7, "title" : "The Scream", "artist" : "Munch", "year" : 1893,
"tags" : [ "Expressionism", "painting", "oil" ] }
{ "_id" : 8, "title" : "Blue Flower", "artist" : "O'Keefe", "year" : 1918,
"price" : NumberDecimal("118.42"),
"tags" : [ "abstract", "painting" ] }使用 $facet 对数据按照三个维度进行统计
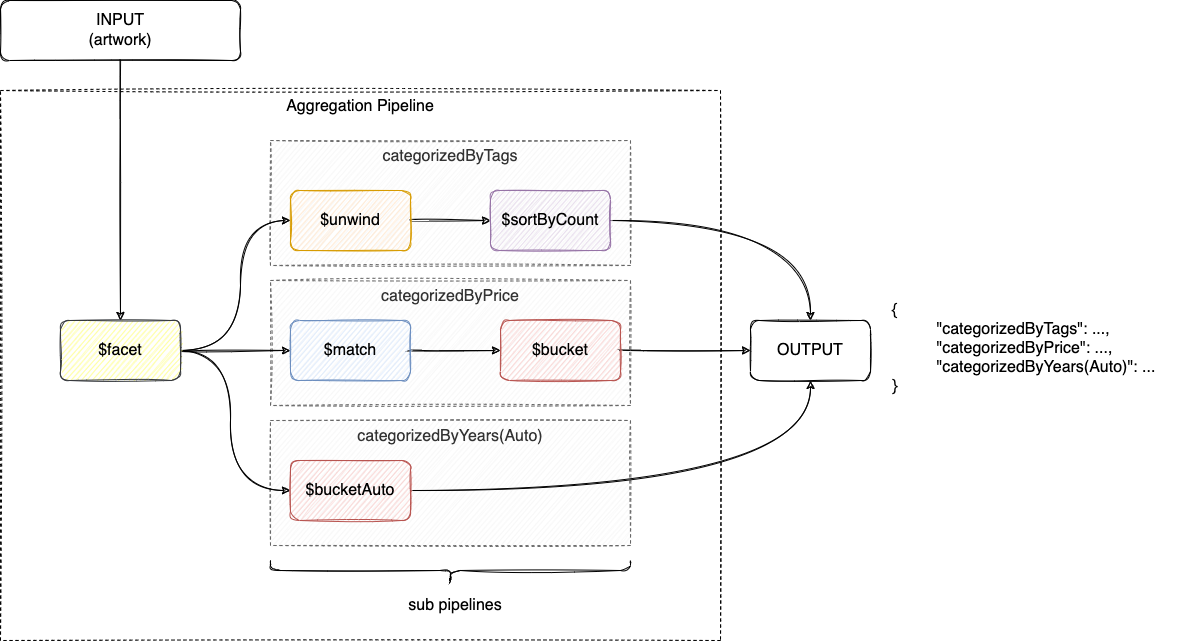
db.artwork.aggregate( [
{
$facet: {
"categorizedByTags": [
{ $unwind: "$tags" },
{ $sortByCount: "$tags" }
],
"categorizedByPrice": [
// Filter out documents without a price e.g., _id: 7
{ $match: { price: { $exists: 1 } } },
{
$bucket: {
groupBy: "$price",
boundaries: [ 0, 150, 200, 300, 400 ],
default: "Other",
output: {
"count": { $sum: 1 },
"titles": { $push: "$title" }
}
}
}
],
"categorizedByYears(Auto)": [
{
$bucketAuto: {
groupBy: "$year",
buckets: 4
}
}
]
}
}
])输出文档
{
"categorizedByYears(Auto)" : [
// First bucket includes the document without a year, e.g., _id: 4
{ "_id" : { "min" : null, "max" : 1902 }, "count" : 2 },
{ "_id" : { "min" : 1902, "max" : 1918 }, "count" : 2 },
{ "_id" : { "min" : 1918, "max" : 1926 }, "count" : 2 },
{ "_id" : { "min" : 1926, "max" : 1931 }, "count" : 2 }
],
"categorizedByPrice" : [
{
"_id" : 0,
"count" : 2,
"titles" : [
"Dancer",
"Blue Flower"
]
},
{
"_id" : 150,
"count" : 2,
"titles" : [
"The Pillars of Society",
"The Great Wave off Kanagawa"
]
},
{
"_id" : 200,
"count" : 1,
"titles" : [
"Melancholy III"
]
},
{
"_id" : 300,
"count" : 1,
"titles" : [
"Composition VII"
]
},
{
// Includes document price outside of bucket boundaries, e.g., _id: 5
"_id" : "Other",
"count" : 1,
"titles" : [
"The Persistence of Memory"
]
}
],
"categorizedByTags" : [
{ "_id" : "painting", "count" : 6 },
{ "_id" : "oil", "count" : 4 },
{ "_id" : "Expressionism", "count" : 3 },
{ "_id" : "Surrealism", "count" : 2 },
{ "_id" : "abstract", "count" : 2 },
{ "_id" : "woodblock", "count" : 1 },
{ "_id" : "woodcut", "count" : 1 },
{ "_id" : "ukiyo-e", "count" : 1 },
{ "_id" : "satire", "count" : 1 },
{ "_id" : "caricature", "count" : 1 }
]
}数组元素拆分为文档 $unwind
$unwind 用于将输入文档中的数组字段解构,为数组中的每一个元素生成一个独立的文档,简单说就是将一条数据拆分为多条。
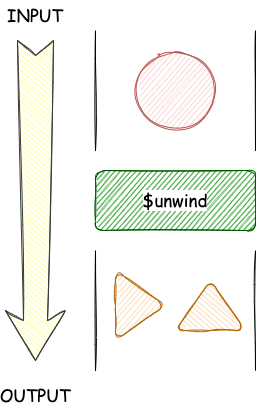
语法如下
{
$unwind:
{
path: <field path>,
includeArrayIndex: <string>,
preserveNullAndEmptyArrays: <boolean>
}
}参数说明
path:数组字段的路径,字段路径需要使用前缀$includeArrayIndex:可选,数组元素的作为新的字段,这里指定了字段名preserveNullAndEmptyArrays:可选,如果设置为true,则如果path参数为 null,没有该字段或者是一个空数组时,$unwind会输出文档,否则不输出,默认值为false
创建集合 inventory ,插入一条数据
db.inventory.insertOne({ "_id" : 1, "item" : "ABC1", sizes: [ "S", "M", "L"] })执行以下命令
db.inventory.aggregate([ { $unwind: "$sizes" } ])该命令会将一条数据拆分为 3 条
{ "_id" : 1, "item" : "ABC1", "sizes" : "S" }
{ "_id" : 1, "item" : "ABC1", "sizes" : "M" }
{ "_id" : 1, "item" : "ABC1", "sizes" : "L" }文档分桶 $bucket
按照指定的表达式和边界对输入的文档进行分组,这里的分组称之为 存储桶,每个桶作为一个文档输出。每一个输出的文档都包含了一个 _id 字段,该字段表示了桶的下边界。

语法如下
{
$bucket: {
groupBy: <expression>,
boundaries: [ <lowerbound1>, <lowerbound2>, ... ],
default: <literal>,
output: {
<output1>: { <$accumulator expression> },
...
<outputN>: { <$accumulator expression> }
}
}
}参数说明
groupBy文档分组表达式boundaries:基于groupBy表达式分组的值数组,数组中的值指定了每一个桶的边界。相邻的两个值分别为桶的上边界和下边界,指定的值类型必须相同并且正序排列。例如[0, 5, 10]创建了两个桶,[0, 5)和[5, 10)default:可选,当groupBy结果不在boundaries的范围内时,将结果放在default指定的桶中(该参数指定了桶的_id)output:可选,指定文档中包含到输出文档中的字段,默认只有_id字段
$bucket 的使用必须满足以下条件之一
- 每一个输入文档经过
groupBy之后都在桶边界范围boundaries内 - 当包含不再桶边界范围内的值时,必须指定
default参数
在 MongoDB 中插入以下文档
db.artists.insertMany([
{ "_id" : 1, "last_name" : "Bernard", "first_name" : "Emil", "year_born" : 1868, "year_died" : 1941, "nationality" : "France" },
{ "_id" : 2, "last_name" : "Rippl-Ronai", "first_name" : "Joszef", "year_born" : 1861, "year_died" : 1927, "nationality" : "Hungary" },
{ "_id" : 3, "last_name" : "Ostroumova", "first_name" : "Anna", "year_born" : 1871, "year_died" : 1955, "nationality" : "Russia" },
{ "_id" : 4, "last_name" : "Van Gogh", "first_name" : "Vincent", "year_born" : 1853, "year_died" : 1890, "nationality" : "Holland" },
{ "_id" : 5, "last_name" : "Maurer", "first_name" : "Alfred", "year_born" : 1868, "year_died" : 1932, "nationality" : "USA" },
{ "_id" : 6, "last_name" : "Munch", "first_name" : "Edvard", "year_born" : 1863, "year_died" : 1944, "nationality" : "Norway" },
{ "_id" : 7, "last_name" : "Redon", "first_name" : "Odilon", "year_born" : 1840, "year_died" : 1916, "nationality" : "France" },
{ "_id" : 8, "last_name" : "Diriks", "first_name" : "Edvard", "year_born" : 1855, "year_died" : 1930, "nationality" : "Norway" }
])下面的操作将会把文档基于 year_born 字段分组,然后基于桶中的文档数量进行过滤
db.artists.aggregate( [
// First Stage
{
$bucket: {
groupBy: "$year_born", // Field to group by
boundaries: [ 1840, 1850, 1860, 1870, 1880 ], // Boundaries for the buckets
default: "Other", // Bucket id for documents which do not fall into a bucket
output: { // Output for each bucket
"count": { $sum: 1 },
"artists" :
{
$push: {
"name": { $concat: [ "$first_name", " ", "$last_name"] },
"year_born": "$year_born"
}
}
}
}
},
// Second Stage
{
$match: { count: {$gt: 3} }
}
] )输出如下
{ "_id" : 1860, "count" : 4, "artists" :
[
{ "name" : "Emil Bernard", "year_born" : 1868 },
{ "name" : "Joszef Rippl-Ronai", "year_born" : 1861 },
{ "name" : "Alfred Maurer", "year_born" : 1868 },
{ "name" : "Edvard Munch", "year_born" : 1863 }
]
}文档自动分桶 $bucketAuto
与 $bucket 功能一样,不过 $bucketAuto 会自动的确定桶的边界,并将文档均匀的分布到桶中。
每一个桶中包含以下内容
_id对象指定了桶的边界count字段包含了桶中的文档数量,如果没有指定output选项,默认会自动包含count字段
语法如下
{
$bucketAuto: {
groupBy: <expression>,
buckets: <number>,
output: {
<output1>: { <$accumulator expression> },
...
}
granularity: <string>
}
}参数说明
buckets指定了桶的个数granularity可选,指定了使用哪种类型的桶边界首选序列(Preferred number) (opens in a new tab),支持的值有R5,R10,R20,R40,R80,1-2-5,E6,E12,E24,E48,E96,E192,POWERSOF2
查询不同年份范围死亡人口统计
db.artists.aggregate([
{ $bucketAuto: { groupBy: "$year_died", buckets: 4} }
])输出如下
{ "_id" : { "min" : 1890.0, "max" : 1927.0 }, "count" : 2 }
{ "_id" : { "min" : 1927.0, "max" : 1932.0 }, "count" : 2 }
{ "_id" : { "min" : 1932.0, "max" : 1944.0 }, "count" : 2 }
{ "_id" : { "min" : 1944.0, "max" : 1955.0 }, "count" : 2 }