Go 二进制文件剖析
汇编码无法撒谎,通过阅读汇编码,我们可以尽可能近的理解我们的计算机芯片在运行什么。这就是为什么反汇编是如此重要!如果你有一个包含恶意企图的二进制文件,反汇编将会曝光它们。如果你无法指出你代码里的性能瓶颈,为了清晰起见,你可以反汇编它。
如果你不懂 x86_64 汇编语言,不要担心,我们大多数人都是这样的。尽管懂一些汇编会让本文变得更加有趣,但是在本文中你无需阅读任何汇编代码。如果你对汇编感兴趣,推荐阅读这篇文章 (opens in a new tab)。
那么什么是反汇编呢?
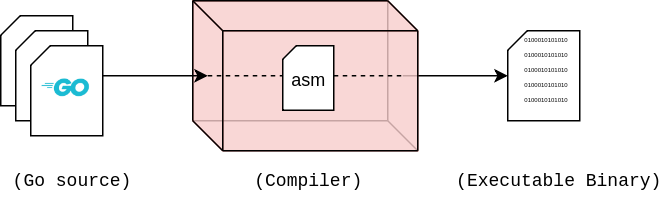
反汇编是一个将编译后的二进制文件转换为汇编码的过程。为了清晰起见,我们先看看我们通常的方式,从源码到编译后的二进制文件:
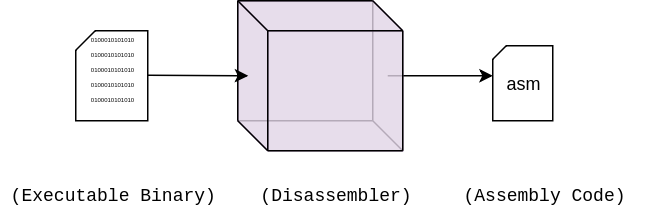
汇编码是一种中间形式。编译器首先会将源代码转换为操作系统体系相关的汇编代码,然后将其汇编为二进制文件。顾名思义,反汇编过程与此相反:
值得庆幸的是,Go 有用一套出色的标准工具链,你可以使用它们进行该过程。你可以通过 go build -gcflags -S program.go 命令编译你的程序,在它转变为 0 和 1 之前看到它的汇编代码。如果你已经有一个编译过的应用程序,你可以通过 go tool objdump binaryFile 命令反汇编你的代码。
我们本可以在这里结束我们的文章,但是我认为如果我们自己来构建一个反汇编器的话会更有意思。
让我们开始吧。
首先,为了构建一个反汇编器,我们需要知道汇编指令中所有的二进制机器码都转换为了什么。为此,我们必须有编译好的二进制文件所对应的体系结构的所有汇编指令的手册。如果你不熟悉这项任务,你可能不会觉得有多困难。但是,存在这多种随时间变化的微体系结构,汇编语法,稀疏记录的指令和编码方案。如果你想进一步分析为什么这么困难,你可以参考这篇文章 (opens in a new tab)。
幸运的是, Capstone 的作者和维护者为我们完成了所有繁杂的工作,它是一个反汇编框架。Capstone 被广泛的接受为编写反汇编工具的标准。尽管具有教育意义,重新实现它仍然是一项十分艰巨的任务,因此在本文中我们不会这么做。在 Go 中使用 Capstone 非常简单,只需要导入名为 gapstone 的 Go 绑定即可:
engine, err := gapstone.New(
gapstone.CS_ARCH_X86,
gapstone.CS_MODE_64,
)
if err != nil {
log.Fatal(err)
}例如,你可以通过 Capstone 插入以下原始字节(以十六进制展示),它将原始字节转换为相应的x86_64指令:
0x64 0x48 0x8B 0xC 0x25 0xF8 0xFF 0xFF 0xFF转换为
mov rcx, qword ptr fs:[0xfffffffffffffff8]在代码中运行起来像是这样:
input := []byte{0x64, 0x48, 0x8B, 0xC, 0x25, 0xF8, 0xFF, 0xFF, 0xFF}
instructions, err := engine.Disasm(input, 0, 0)
if err != nil {
log.Fatal(err)
}
for _, instruction := range instructions {
fmt.Printf("0x%x:\t%s\t\t%s\n", instruction.Address, instruction.Mnemonic, instruction.OpStr)
}执行命令
$~ go run main.go
0x0: mov rcx, qword ptr fs:[0xfffffffffffffff8]使用这些工具,我们唯一需要做的就是从二进制文件中提取原始字节,将其传递给 Capstone 引擎。
当你在笔记本电脑上编译 Go 程序时,输出的二进制文件可能会时默认的 64 位 ELF(Executable Linkable Format)格式。ELF 分为多个部分,每一部分都有其独特的用途,例如存储版本信息,程序元数据或可执行代码。ELF是二进制文件的一种被广泛接受的标准,在 Go 中,使用 debug/elf 包 可以轻松的与它们进行交互。ELF 格式规范有些复杂,但是为了便于反汇编,我们实际上只关心符号表和文本部分。让我们看下
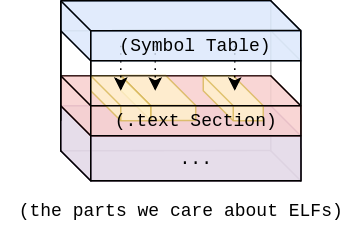
首先,我们先定义术语“符号(symbol)”。它是我们的代码中所有具有可识别名称的对象。变量,函数,类型和常量都是符号。Go编译器编译每一个符号然后存储他们的引用信息到符号表中。我们可以看下在 debug/elf 包中定义的 Symbol 结构体,符号表中每一条记录都包含符号名称,大小,内存偏移和类型:
// A Symbol represents an entry in an ELF symbol table section.
type Symbol struct {
Name string
Info byte
Other byte
Section SectionIndex
Value uint64
Size uint64
}尽管还不清楚这里的命名约定,但是内存偏移存储在 Value 字段中。内存偏移是指从.text部分开始的地址。该部分存储了程序中定义的可执行指令(函数符号)。通过命名约定还不清楚的一个字段是 Info,这个字段是表示符号类型的特殊值。为了简化我们的反汇编程序,我们只想看下函数,因此,在进行一些钻研之后,我发现 Go 使用 2 和 8 作为函数的符号。
利用这些知识,我们想从 ELF 二进制文件中提取出符号表,然后遍历每个符号就可以找到进行反汇编的字节位置:
// Open the ELF file
elfFile, err := elf.Open(path)
if err != nil {
log.Fatalf("error while opening ELF file %s: %+s", path, err.Error())
}
// Extract the symbol table
symbolTable, err := elfFile.Symbols()
if err != nil {
log.Fatalf("could not extract symbol table: %s", err.Error())
}
// Traverse through each symbol in the symbol table
for _, symbol := range symbolTable {
/*
symbol.Info lets us tell if this symbol is a function that we want to disassemble
symbol.Value gives us the offset from the start of the .text section
symbol.Size lets us calculate the full address range of this symbol in the .text section
*/
}接下来我们计算下.text部分的字节数组的开始和结束索引位置。对于每一个符号,我们需要从.text 部分的起始地址中减去它的 Value;这样我们就得到了它的开始索引。计算结束位置只需要开始索引加上符号的大小就可以了。从哪里我们就可以收集字节并且通过 Capstone 来解析它们了。
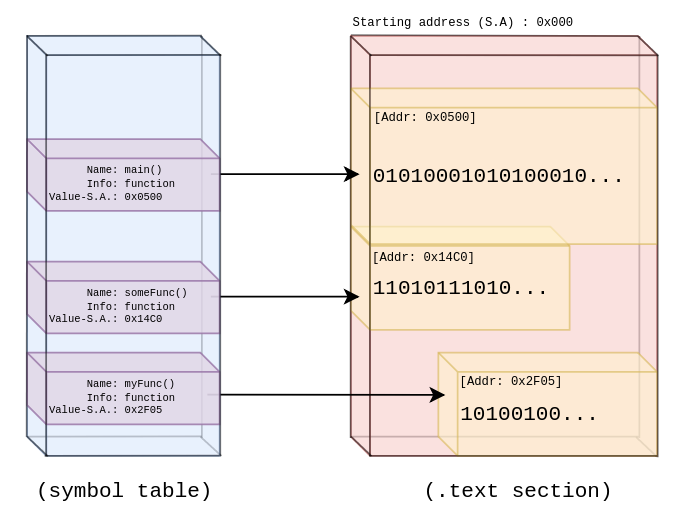
现在我们已经基本完成了。我们将会打开 .text 部分获取开始地址和原始数据,然后为每个符号执行地址计算,通过 Capstone 解析这些数据,然后输出得到的指令:
// extract the .text section
textSection := elfFile.Section(".text")
if textSection == nil {
log.Fatal("No text section")
}
// extract the raw bytes from the .text section
textSectionData, err := textSection.Data()
if err != nil {
log.Fatal(err)
}
// traverse through the symbol table
for _, symbol := range symbolTable {
// skip over any symbols that aren't functinons/methods
if symbol.Info != byte(2) && symbol.Info != byte(18) {
continue
}
// skip over empty symbols
if symbol.Size == 0 {
continue
}
// calculate starting and ending index of the symbol within the text section
symbolStartingIndex := symbol.Value - textSection.Addr
symbolEndingIndex := symbolStartingIndex + symbol.Size
// collect the bytes of the symbol
symbolBytes := textSectionData[symbolStartingIndex:symbolEndingIndex]
// disasemble the symbol
instructions, err := engine.Disasm(symbolBytes, symbol.Value, 0)
if err != nil {
log.Fatalf("could not disasemble symbol: %s", err)
}
// print out each instruction that's part of this symbol
fmt.Printf("\n\nSYMBOL %s\n", symbol.Name)
for _, ins := range instructions {
fmt.Printf("0x%x:\t%s\t\t%s\n", ins.Address, ins.Mnemonic, ins.OpStr)
}
}这就是全部了!完整的程序在这里 (opens in a new tab)。通过利用 Go 生态提供的一些非常强大的工具,我们能够使用不到 75 行代码就构建出了一个功能全面的反汇编程序!
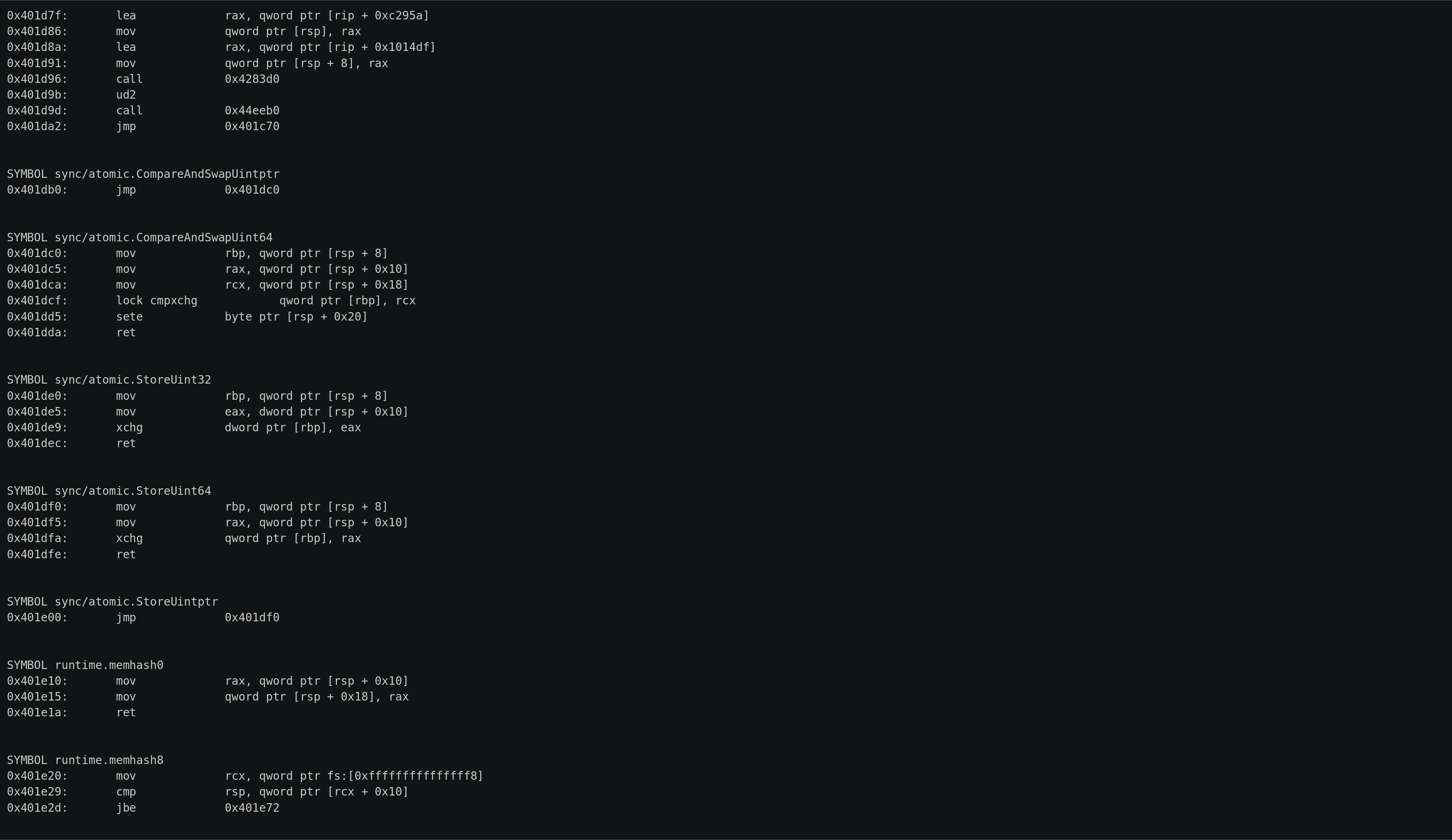
下面是我们的反汇编程序的运行情况: